Senior cloud engineers running your infrastructure on a defined service model. Monitoring, lifecycle management, cost governance, security drift detection, capacity planning, and compliance support — across AWS, Azure, GCP, Oracle Cloud, and hybrid environments — delivered as a fully accountable managed service.
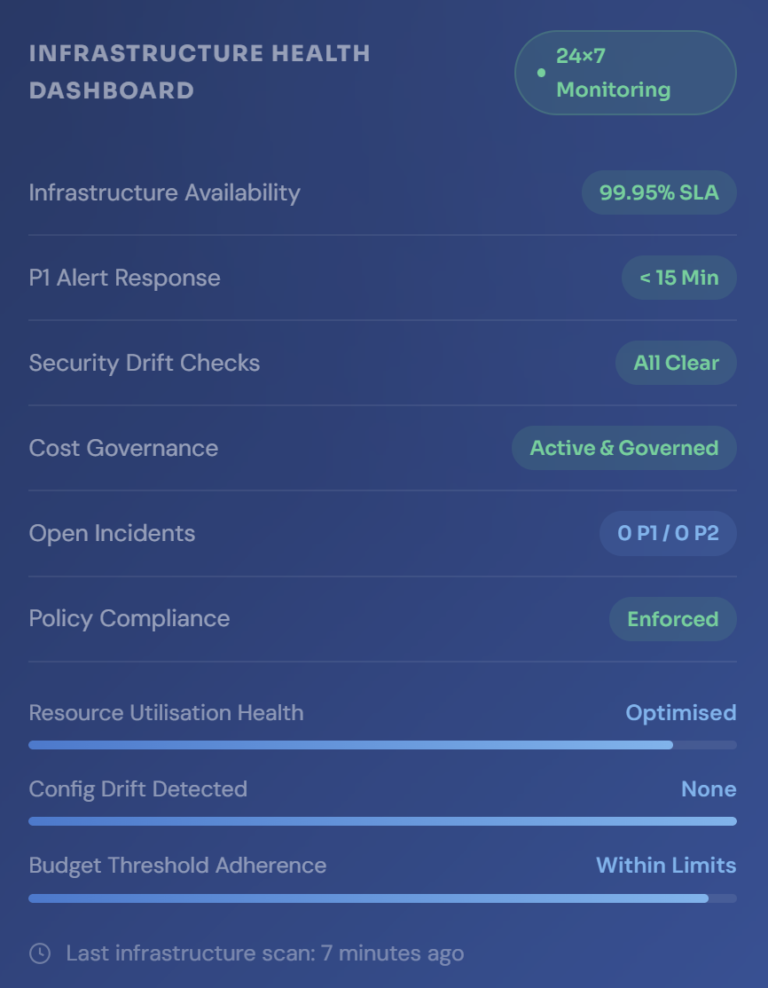
Infrastructure Availability SLA
P1 Incident Response Time
AWS, Azure, GCP, OCI & Hybrid
Senior-Led Engagements
Every Gigamatics cloud managed service is structured around nine defined operational pillars — each
governed, documented, and adapted to your environment, scale, and compliance obligations.
Continuous 24×7 monitoring of your entire cloud estate — compute, storage, networking, and platform services — with proactive alerting before degradation reaches your users or workloads.
Structured management of the full lifecycle of compute instances, storage volumes, and network resources — from provisioning through rightsizing, patching, and decommissioning.
Infrastructure-as-Code governed provisioning and configuration management — ensuring environments are consistent, reproducible, and free from configuration drift across all accounts and regions.
Continuous cloud cost monitoring integrated into day-to-day operations — with rightsizing recommendations, waste elimination, commitment utilisation tracking, and budget governance enforced as standard.
Governance frameworks, cloud policies, and guardrails that enforce standards across your environment — preventing non-compliant resource creation, enforcing tagging, and maintaining accountability at scale.
Continuous monitoring of your cloud security posture against defined baselines — with automated detection of configuration drift, exposure, and policy violations before they become exploitable risks.
Structured incident response with defined severity classifications, response SLAs, and documented root cause analysis — ensuring cloud incidents are resolved quickly, thoroughly, and without recurrence.
Forward-looking analysis of resource consumption, workload growth, and demand patterns — ensuring scaling decisions are made on data, capacity constraints are avoided, and infrastructure investments are justified.
Continuous audit log management, compliance evidence preparation, and active support during regulatory reviews — ensuring your cloud infrastructure meets its obligations under ISO 27001, SOC 2, GDPR, and applicable frameworks.
Gigamatics Managed Cloud & Infrastructure Operations is not a reactive helpdesk. It is a proactive, structured service — built around senior cloud engineers, defined SLAs, and governance frameworks that keep your cloud estate performing, secure, and cost-controlled at all times.
Your environment is assigned to a named senior engineer who understands your architecture, workload patterns, and operational history — not passed to a generic NOC team.
Every engagement begins with a comprehensive cloud estate assessment — documenting architecture, configuration standards, security posture, cost allocation, and existing risks before operations begin.
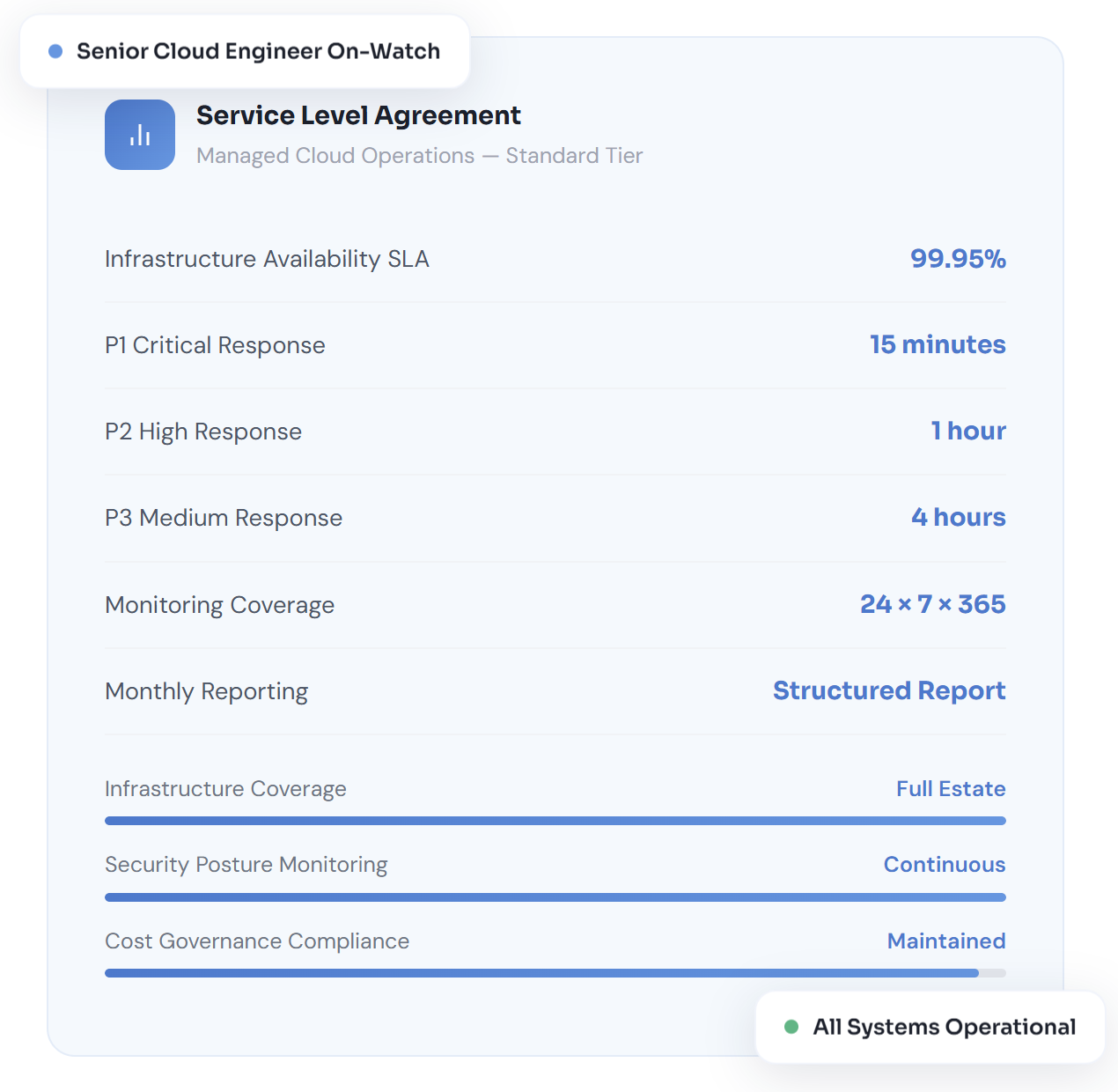
Response times, availability targets, and service standards are contractually bound and actively measured — with monthly SLA performance reports delivered directly to your leadership team.
A structured monthly report covering infrastructure health, incidents, security posture, cost trends, and capacity outlook — giving engineering and finance stakeholders a complete operational picture.
Cloud architecture guidance, migration planning input, and FinOps advisory are part of the engagement — not billed as separate consulting hours. Your operations team is also your cloud advisor.
Every operational activity runs on a defined cadence. Nothing is ad-hoc, nothing is forgotten,
and every task is tracked and reported against an accountable schedule.
|
Activity
|
Description
|
Cadence
|
|---|---|---|
|
Infrastructure Availability Monitoring
|
Real-time monitoring of all compute, storage, network, and platform services with automated alerting on threshold breaches and availability events.
|
Continuous
|
|
Security Drift & Posture Monitoring
|
Continuous scanning of cloud configurations against defined security baselines — alerting on misconfigurations, public exposure, and IAM drift as they occur.
|
Continuous
|
|
Cost Monitoring & Anomaly Alerting
|
Real-time monitoring of cloud spend against defined budgets and thresholds — with immediate alerts on unexpected cost spikes or anomalies before they compound.
|
Continuous
|
|
Alert Triage & Incident Response
|
Assessment, prioritisation, and resolution of all generated alerts with P1 escalation to the named senior cloud engineer within 15 minutes of detection.
|
Continuous
|
|
Resource Health & Performance Check
|
Daily review of compute utilisation, network performance, storage consumption, and workload health — with tuning actions initiated where performance degradation is identified.
|
Daily
|
|
Backup & Snapshot Verification
|
Verification of all automated backup and snapshot jobs — confirming successful execution, retention compliance, and cross-region replication where applicable.
|
Daily
|
|
Cost Optimisation Review
|
Weekly analysis of idle resources, rightsizing candidates, and commitment utilisation — with a prioritised list of optimisation actions presented for approval.
|
Weekly
|
|
Configuration Drift Assessment
|
Structured comparison of live environment configuration against approved baselines — with identified drift documented and remediation scheduled through change management.
|
Weekly
|
|
Capacity Trend Review
|
Analysis of resource consumption growth rates and forecast modelling — to identify approaching capacity constraints and plan scaling actions in advance.
|
Weekly
|
|
Patch & Update Management
|
Evaluation, scheduling, and deployment of OS patches, platform updates, and security patches — through a risk-qualified change management process with rollback capability.
|
Monthly
|
|
IAM & Access Control Review
|
Review of cloud IAM roles, policies, service accounts, and privilege assignments — identifying over-permissions, dormant accounts, and policy violations.
|
Monthly
|
|
Compliance & Audit Reporting
|
Collection of audit trail evidence, policy compliance reports, and security posture summaries — packaged per framework requirements and delivered to stakeholders.
|
Monthly
|
|
Incident Root Cause Analysis
|
Formal RCA report produced for every P1 or P2 incident — documenting root cause, timeline, resolution actions, and preventive measures to avoid recurrence.
|
Post-Incident
|
Most cloud managed services are reactive support desks staffed by generalists
following runbooks. Gigamatics operates on a fundamentally different model —
senior engineers, proactive governance, and consulting embedded in every engagement.
Your cloud environment is managed by engineers who have designed, migrated, and operated production infrastructure at enterprise scale — not junior operators following ticket queues. Expertise is present in every interaction.
Our monitoring frameworks, drift detection, and capacity review cadences are built to surface problems before they become incidents. We resolve issues before your users see them — not after they file support tickets.
FinOps is not a separate engagement. Cost monitoring, rightsizing, waste elimination, and budget governance are embedded in the day-to-day operational service — ensuring your cloud bill is continuously managed, not periodically reviewed.
As your cloud estate grows — new accounts, new regions, new services — our governance frameworks, policy controls, and operational procedures scale with it. Consistency is engineered in, not bolted on after the fact.
Repeatable, validated results across cloud estates of every scale, maturity, and complexity.
Proactive monitoring, rapid incident response, and continuously validated failover configurations deliver near-continuous availability across complex, multi-region cloud environments.
With FinOps governance embedded in the operational service, clients consistently reduce cloud spend through rightsizing, waste elimination, and commitment optimisation — sustained over time, not just at the start of an engagement.
Continuous security posture monitoring and weekly drift assessments ensure that environment deviations from approved baselines are detected and remediated before they create risk or compliance exposure.
Senior cloud engineers with deep environment knowledge, documented runbooks, and pre-defined escalation paths resolve critical infrastructure incidents three times faster than unmanaged or generalist-staffed environments.
Every client under our managed service has entered compliance audits with complete cloud infrastructure evidence packages prepared and a senior engineer available — passing first time, on time.
By shifting to a proactively managed model, internal engineering teams are freed from operational firefighting — with effort redirected to product development, platform innovation, and strategic initiatives.
A structured conversation covering your current cloud landscape, operational gaps, cost posture, and security concerns — no commitment required.
For qualifying engagements, a documented assessment of your cloud health, cost posture, security gaps, and recommended managed service scope.
You speak with the practitioner who would manage your environment — not a pre-sales team. Every conversation is grounded in technical reality.
Have a specific question about your cloud estate, team structure, or what’s covered? Our cloud engineers are ready to talk.
Many clients engage Gigamatics to augment existing cloud teams — providing 24×7 out-of-hours coverage, specialist depth for specific platforms, FinOps governance, or additional capacity during scaling events. We work alongside your team, not instead of it.
Onboarding begins with a structured cloud estate assessment — typically two to three weeks — covering every account, region, service configuration, security posture, cost allocation baseline, existing monitoring, and known operational gaps. This produces a documented environment baseline that informs SLA targets, monitoring thresholds, and runbook design. Full operational coverage goes live only after this baseline is established and validated.
Yes. Multi-cloud and hybrid environments are a core part of our managed service model. We unify monitoring, governance, cost allocation, and incident management across AWS, Azure, GCP, Oracle Cloud, and on-premise infrastructure under a single operational framework — so you receive consistent visibility and accountability regardless of where workloads run.
Native cloud security tools — AWS Security Hub, Microsoft Defender for Cloud, GCP Security Command Centre — surface findings, but rarely have a governed process for reviewing, prioritising, and remediating them. We provide the operational layer on top: daily posture review, drift detection, alert triage, and a change-managed remediation workflow that ensures findings are acted on — not just logged.
Cost monitoring, anomaly alerting, rightsizing recommendations, waste identification, and commitment utilisation tracking are embedded in the core managed service — not billed separately. We treat cloud cost governance as an operational responsibility, not a consulting add-on. For organisations requiring a deeper FinOps engagement — tagging framework redesign, showback implementation, or savings plan strategy — we offer structured FinOps consulting as a complementary service.
All changes — including patches, configuration updates, rightsizing actions, and infrastructure modifications — follow a documented change management process. Each change includes a change record, impact assessment, rollback plan, and requires approval from your designated authority before implementation. Emergency changes during incident response follow an expedited process with retrospective documentation. Every change is auditable.
The monthly report covers infrastructure availability and SLA performance, incident summary and resolution status, security posture and drift findings, cost trends and optimisation actions taken, capacity utilisation and forecasts, patch and update status, and recommended actions for the coming period. It is designed to give both engineering and finance leadership a complete, accurate picture of cloud operations in a single document.
Connect with our team to discuss your data, cloud, or security landscape and define a clear, structured path forward.
Testimonials
Pricing
Single Project
Single Prost
Portfolio