We design and implement enterprise AI and intelligent automation programmes — translating AI potential into structured, governed, measurable capability. Not pilots that don’t scale, not experimentation without purpose, but AI systems that integrate into your operations, produce auditable outputs, and improve as your business grows.

Most AI initiatives fail not because the models are wrong, but because the surrounding architecture is not ready for them. Data quality is insufficient, governance is absent, deployment is fragile, and the business case was never precise enough to measure. We address AI as a systems engineering problem — not a model selection exercise — and build programmes that survive contact with production.
Technology-agnostic AI strategy that begins with business outcomes and works backwards to use cases, data requirements, and technology choices.
Production LLM systems require prompt engineering, retrieval architecture, evaluation frameworks, and latency controls — not just an API key.
End-to-end ML system design — from feature engineering and model selection through training pipelines, evaluation, and production serving with monitoring.
IPA combines RPA execution with AI-powered decision-making — enabling automation of processes that require classification, extraction, and judgment.
MLOps is to AI what DevOps is to software — the engineering discipline that makes production AI systems reproducible, observable, and continuously maintainable.
AI systems without governance create regulatory exposure, reputational risk, and operational liability. Governance is not a checklist — it is an architectural requirement.
AI engagements fail when technology selection precedes problem definition. We begin with the business outcome, work backwards through data readiness, architecture, and governance, and only then make technology decisions. Every stage has a defined output before the next begins.
Structured discovery across your operations to identify where AI creates measurable, defensible value — not just where it is technically interesting. Output: a prioritised use case register with business case, feasibility score, data readiness assessment, and a recommended sequencing strategy before any technology commitment is made.
Design of the target-state AI architecture — model selection rationale, data pipeline design, serving architecture, MLOps platform, and governance controls. Includes a data readiness assessment identifying gaps that must be closed before model training begins. No implementation proceeds without a reviewed and approved architecture document.
Development of the AI system against a documented specification — feature engineering, model training, evaluation against defined performance thresholds, and integration into the target operational environment. Every model ships with a model card documenting training data, performance characteristics, known limitations, and operational constraints.
Controlled production deployment — canary rollout, A/B validation, performance benchmarking against the baseline, and observability configuration. MLOps monitoring is established before go-live, not after. Drift detection thresholds, retraining triggers, and operational runbooks are in place before the system handles production traffic at full scale.
Most AI programmes stall between proof of concept and production. The model worked in the notebook. It failed in the pipeline. It degraded six weeks after deployment. These are not model problems — they are engineering and governance problems. We design AI systems to survive production from the first line of architecture.
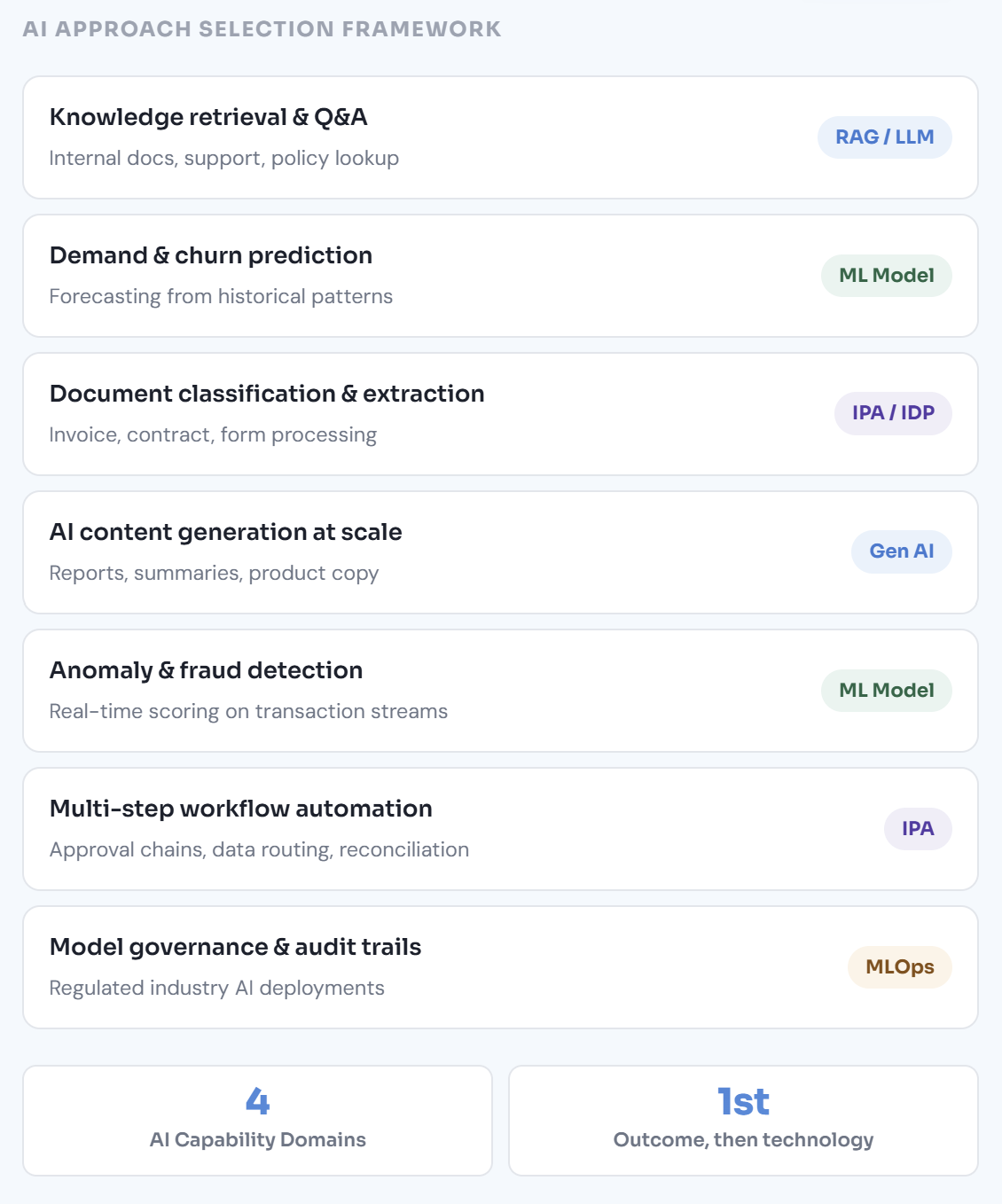
Technology-led AI programmes choose a model and then search for problems it can solve. Outcome-led programmes start with a business problem — a measurable inefficiency, a decision that takes too long, a prediction that would change behaviour — and then work backwards to the simplest AI approach that addresses it. The simplest approach is usually the correct one: a well-designed ML model often outperforms a complex LLM pipeline on structured prediction tasks, at a fraction of the cost and with far better auditability. We run a technology-agnostic opportunity assessment before recommending any AI approach, because the recommendation should be justified by the problem, not by what is currently fashionable.
The gap between a working prototype and a production AI system is where most AI programmes fail — and it is an engineering gap, not a data science gap. Production AI requires a reproducible training pipeline, a model registry with versioning and lineage, a serving infrastructure with latency guarantees, a monitoring stack that detects drift before it causes degraded predictions, and a retraining process that can respond to distribution shift without human intervention for every cycle. None of these exist in a Jupyter notebook. We engineer the production system from the beginning — not as an afterthought when the data science team declares the model ready. MLOps is not an optional add-on. It is the architecture that makes the model useful.
Large language models are powerful, but they are not reliable by default. They hallucinate. They are sensitive to prompt phrasing. Their outputs are non-deterministic. They can be manipulated through adversarial inputs. They are expensive to operate at scale without careful architecture. Building a production LLM application requires retrieval architecture that grounds responses in verified data, prompt engineering that produces consistent outputs, evaluation frameworks that measure accuracy, safety, and cost simultaneously, guardrails that detect and block harmful or off-policy outputs, and observability that makes every model call auditable. We build LLM systems that engineering teams can operate with confidence — not demos that collapse under edge cases in week two of real usage.
Organisations that treat AI governance as a post-deployment review will eventually deploy a system that produces a biased output, makes an unexplainable decision, or violates a data regulation they were not tracking. Governance must be designed into the AI system — in the data lineage, in the model card, in the bias evaluation, in the audit trail, in the human oversight protocol. The EU AI Act is creating binding obligations for high-risk AI systems across every regulated sector. GDPR data minimisation principles constrain what data AI systems can use for training. Sector-specific regulators are increasingly asking for explainability that current LLM architectures cannot provide by default. We design AI governance frameworks that satisfy these constraints without making AI systems impractical to build or operate — because governance and capability are not opposites when the architecture is designed correctly from the start.
Structured engagement types — each with a defined scope, measurable success criteria,
and a senior AI practitioner accountable from discovery through to production validation.
A structured AI strategy engagement — assessing your operations for AI opportunity, sizing business value, evaluating data readiness, and producing a sequenced roadmap with phased delivery milestones. Technology-agnostic and outcome-led: the roadmap is justified by business impact, not technology enthusiasm.
End-to-end implementation of production generative AI applications — RAG systems, enterprise copilots, and AI agent workflows — designed for reliability, auditability, and cost control from day one, not retrofitted after the first production incident.
Full-cycle ML engineering — from feature store design and model training through to production serving, performance monitoring, and automated retraining. Built for durability in production, not just accuracy in the validation set.
A structured AI governance framework that makes your AI systems auditable, explainable, and compliant — addressing EU AI Act obligations, GDPR data constraints, and sector-specific regulatory requirements with enforceable controls rather than policy statements.
An AI system deployed without operational support will degrade —through
data drift, model decay, infrastructure changes, and the absence of a retraining
cadence. The surrounding platform must also remain reliable, governed,
and cost-controlled for AI to deliver its intended value over time.
AI inference workloads place distinct performance and reliability demands on the underlying platform. Managed platform reliability ensures the serving infrastructure that your models depend on remains available, performant, and SLO-governed.
AI workloads — training, fine-tuning, and inference — consume cloud resources at scale. Managed cloud operations ensures compute, storage, and GPU resources are governed, cost-controlled, and availability-assured across your AI platform.
Feature stores, vector databases, and training data pipelines require the same operational discipline as any production database. Managed database operations covers availability, performance, and integrity of the data layer that AI systems depend on.
AI systems introduce new attack surfaces — prompt injection, data poisoning, model extraction, and PII leakage through model outputs. Managed security operations extends your control framework to cover AI-specific risks continuously, not just at deployment.
Whether you’re identifying your first AI use case, accelerating a stalled pilot, building an LLM application, or designing the governance framework for a regulated AI deployment — we’d like to start with a conversation about your specific situation, not a generic AI pitch.
Two to four week technology-agnostic assessment — prioritised use case register, data readiness analysis, and a sequenced AI roadmap with investment estimates.
Scoped engineering engagement to convert a working AI pilot into a production system — with MLOps, monitoring, governance, and operational handover built in.
You speak with the senior AI practitioner who would lead your engagement — technically grounded, no pre-sales layer, no obligation.
Every AI engagement closes with a documented comparison between the baseline and the final state — not
a proof of concept that was never intended to survive the presentation room.
Technical and strategic outputs delivered at defined phase gates — reviewed against success criteria, formally accepted, and structured for operational handover to your engineering team.
The principles that govern how every AI engagement is structured, measured, and closed — ensuring clear governance, defined success criteria, disciplined execution, and transparent collaboration from initiation to operational handover.
Every engagement begins with a defined business outcome and measurable success criteria. Technology selection follows problem definition — never the reverse.
Engagements close when the AI system is operating in production, not when the model is trained. Deployment, monitoring, and observability are in scope — not optional extras.
Model cards, bias evaluations, audit trails, and approval controls are designed in from the start — not added after a compliance team asks for them.
Every deployed model has a documented owner, retraining trigger, drift threshold, and operational runbook. AI systems without operational accountability are liabilities.
Every engagement closes with a documented baseline-to-outcome comparison — accuracy, latency, automation rate, cost reduction, or decision quality — whatever was defined at the start.
Engineering teams receive structured knowledge transfer — not documentation they will never open. The AI programme must be operationally independent of our practitioners after handover.
Connect with our team to discuss your data, cloud, or security landscape and define a clear, structured path forward.
Testimonials
Pricing
Single Project
Single Prost
Portfolio