We design, migrate, and govern enterprise data platforms — from legacy warehouse modernisation and Lakehouse architecture to pipeline engineering, analytics enablement, and data governance frameworks built for long-term operational use.
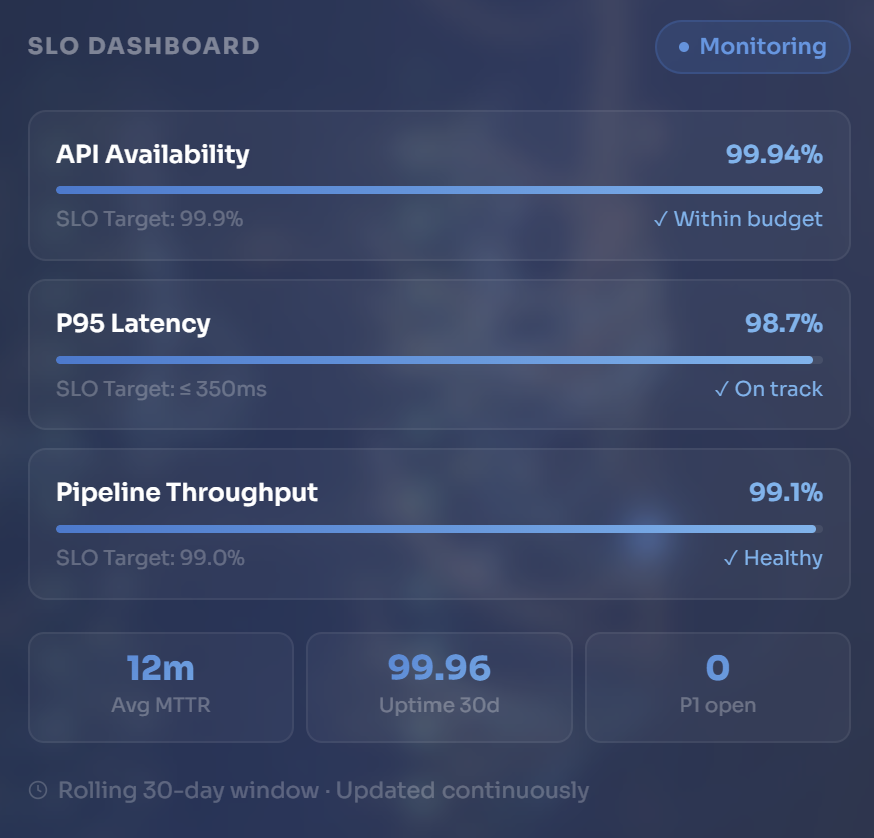
Platform failures are not technology failures — they are architecture and process failures. Systems that lack defined reliability targets, observable failure signals, and structured incident response will degrade under scale, regardless of the cloud provider or the technology stack. We address each discipline as a structured engineering engagement with measurable outputs.
Designing reliability from the ground up — defining what good looks like, how it's measured, and what happens when the budget runs out.
Building observability into the platform — not bolted on as a monitoring afterthought — so that failure signals are clear, correlated, and actionable.
Includes
Structured incident response turns a chaotic event into a managed process — reducing MTTR, protecting user trust, and generating learning that prevents recurrence.
Performance problems are architecture problems. We identify the root constraints — at the application, infrastructure, or data layer — and engineer durable improvements against measured baselines.
Reactive scaling is fire-fighting. We design capacity models and scaling architectures that match growth ahead of demand, with defined saturation thresholds and automated response.
Reliability without governance decays as teams grow and systems change. We design the operating model, review cadence, and accountability structures that keep reliability a first-class engineering concern.
Reliability engagements follow a structured progression — understand the current failure landscape, design the reliability architecture, implement with measurement built in from the start, then operate with continuous improvement as the default.
Structured review of your current reliability posture — incident history analysis, MTTR/MTTD measurement, SLO gap assessment, observability coverage audit, and on-call load evaluation. Output: a documented reliability baseline with prioritised improvement recommendations before any architecture decisions are made.
Design of the target-state reliability operating model — SLI/SLO definitions for each critical user journey, error budget policies, observability stack architecture, alerting strategy, and incident response processes. Every design decision is documented and reviewed before implementation begins.
Implementation of the reliability architecture — observability instrumentation, SLO dashboards, alerting configuration, incident response tooling, runbooks, and on-call rotation design. Measurement is built into every component from day one, not added later when something breaks.
Validation that the implemented reliability programme delivers measurable improvement — load testing, chaos engineering exercises to surface hidden failure modes, SLO burn rate validation, and MTTR benchmarking against baseline. Continued optimisation until improvement targets are confirmed in production.
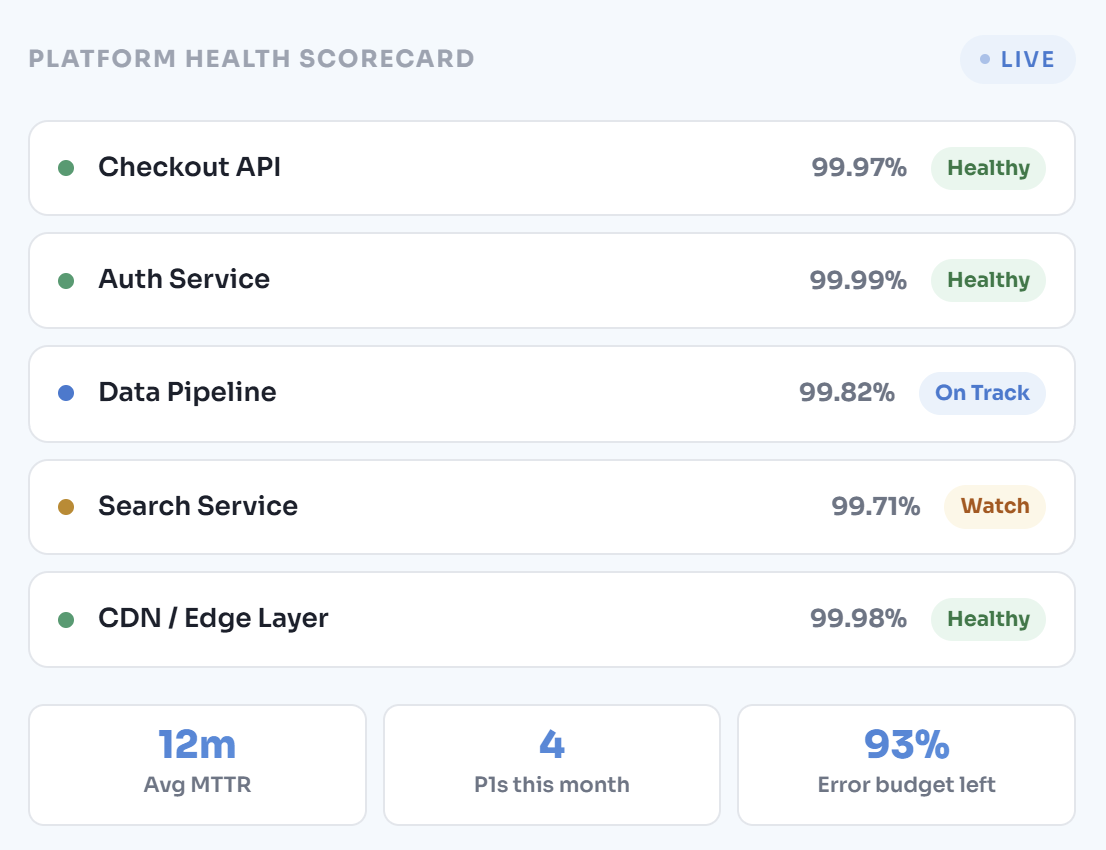
Platform instability is not bad luck — it is a predictable outcome of systems designed
without reliability targets, deployed without observability, and operated without structured incident response.
Every reliability failure has an architectural cause. We find it and engineer it out.
Most organisations instrument their systems first — adding metrics, dashboards, and alerts — and then try to derive reliability targets from the data they have. This inverts the correct sequence. Reliability targets must be defined from user expectations and business impact first, then the instrumentation is designed to measure whether those targets are being met. An SLO that is not grounded in a real user journey is a vanity metric. We define the target first, build the measurement second, and only then assess whether the current system meets it.
Without error budgets, reliability is a conversation between engineering and management that never reaches resolution — because there is no shared, objective measure of how reliable "reliable enough" actually is. Error budgets make the tradeoff explicit: when the budget is healthy, the team can invest in velocity and new features. When the budget is burning, reliability work takes priority. This transforms reliability from a cost centre argument into an engineering policy that engineering teams can self-govern. We design error budget policies that work in practice, not just in theory.
Traditional monitoring — threshold-based alerts on known metrics — tells you that latency has exceeded 500ms. Observability tells you which downstream service caused it, which deployment introduced the regression, which customer cohort is affected, and what the error rate is on every call path through the system. The difference determines whether your incident response takes twelve minutes or three hours. We design observability architectures — not monitoring stacks — built on the three pillars of metrics, structured logs, and distributed traces, with dashboards that answer questions rather than just report numbers.
Toil — manual, repetitive operational work that scales linearly with the system — is the enemy of sustained reliability. Organisations that respond to growth by adding on-call engineers rather than automating operational tasks will eventually reach a breaking point where the humans cannot scale fast enough. We design reliability programmes with explicit toil reduction targets: identifying the manual operational tasks consuming engineering time, automating them systematically, and measuring the reduction in on-call burden over time. The goal is a reliability programme that improves as the platform scales, not one that degrades under the operational weight of its own complexity.
Structured service areas — each with defined scope, measurable outputs, and a senior SRE practitioner
accountable from assessment through to validated improvement in production.
A structured engagement to define, implement, and operationalise an SRE-based reliability programme — from SLO target setting through to error budget governance and on-call design, producing a reliability operating model your engineering teams can sustain independently.
Design and implementation of full-stack observability — structured to surface failure signals before users notice them, correlate symptoms to root causes, and give engineering teams the context they need to respond effectively to any incident
A structured performance investigation and remediation engagement — diagnosing latency, throughput, and saturation problems at every layer of your platform, engineering improvements against documented baselines, and validating results under sustained production-representative load.
Design and implementation of a structured incident management system — from detection and classification through response coordination, communication, and post-incident learning — reducing MTTR and building the operational discipline that prevents category-of-incident recurrence.
Two to three week assessment — MTTR/MTTD baseline, SLO gap analysis, observability audit, and a prioritised improvement roadmap with effort estimates.
Focused performance engineering engagement — baseline measurement, bottleneck identification, remediation, and load-validated improvement across the layers causing the problem.
Direct Practitioner Access You speak with the senior SRE practitioner who would lead your engagement — technically grounded, no pre-sales layer, no obligation.
A reliability programme implemented and then left unmanaged will decay as
systems change, teams turn over, and the operational discipline erodes.
Our managed services practice operates the reliability capability we’ve built —
maintaining SLO governance, responding to incidents, and continuously
improving platform performance.
SRE-led managed operations — ongoing SLO monitoring, incident response, error budget tracking, and reliability reporting — sustaining the reliability programme as a continuous operational practice.
Managed cloud infrastructure operations across AWS, Azure, and GCP — ensuring the underlying compute, network, and storage layers that platform reliability depends on are consistently governed and maintained.
Database performance, availability, and backup operations — because platform reliability is only as strong as its data layer. Managed database ops ensures query performance, replication health, and recovery capability are continuously maintained.
Continuous security posture monitoring alongside platform reliability operations — ensuring that reliability improvements don’t introduce security exposure, and that control frameworks remain current as the platform evolves.
Every reliability engagement is measured against one outcome: demonstrable,
quantified improvement in platform reliability and performance — validated in
production, not just documented in a report.
Technical and programme outputs delivered at each phase gate — reviewed, measured against baseline, and formally accepted before the engagement closes.
Every reliability engagement is governed by explicit quality standards — from baseline measurement through to validated improvement in production.
No reliability engagement proceeds without a documented current-state baseline. Improvement can only be measured if the starting point is defined.
Every engagement closes with a documented comparison between baseline and final state — MTTR, SLO performance, error budget burn rate, and latency metrics.
Reliability improvements are validated in production — not just in a test environment. If it doesn't hold under real traffic, it doesn't count.
On-call burden and operational toil are measured at baseline and at closure. Toil reduction is a deliverable — not a side effect.
Engineering teams receive structured knowledge transfer — not just documentation. The reliability programme must survive our exit from the engagement.
SLO governance, error budget tracking, and reliability review cadence are formally handed over — with reporting frameworks your leadership can operate independently.
Connect with our team to discuss your data, cloud, or security landscape and define a clear, structured path forward.
Testimonials
Pricing
Single Project
Single Prost
Portfolio